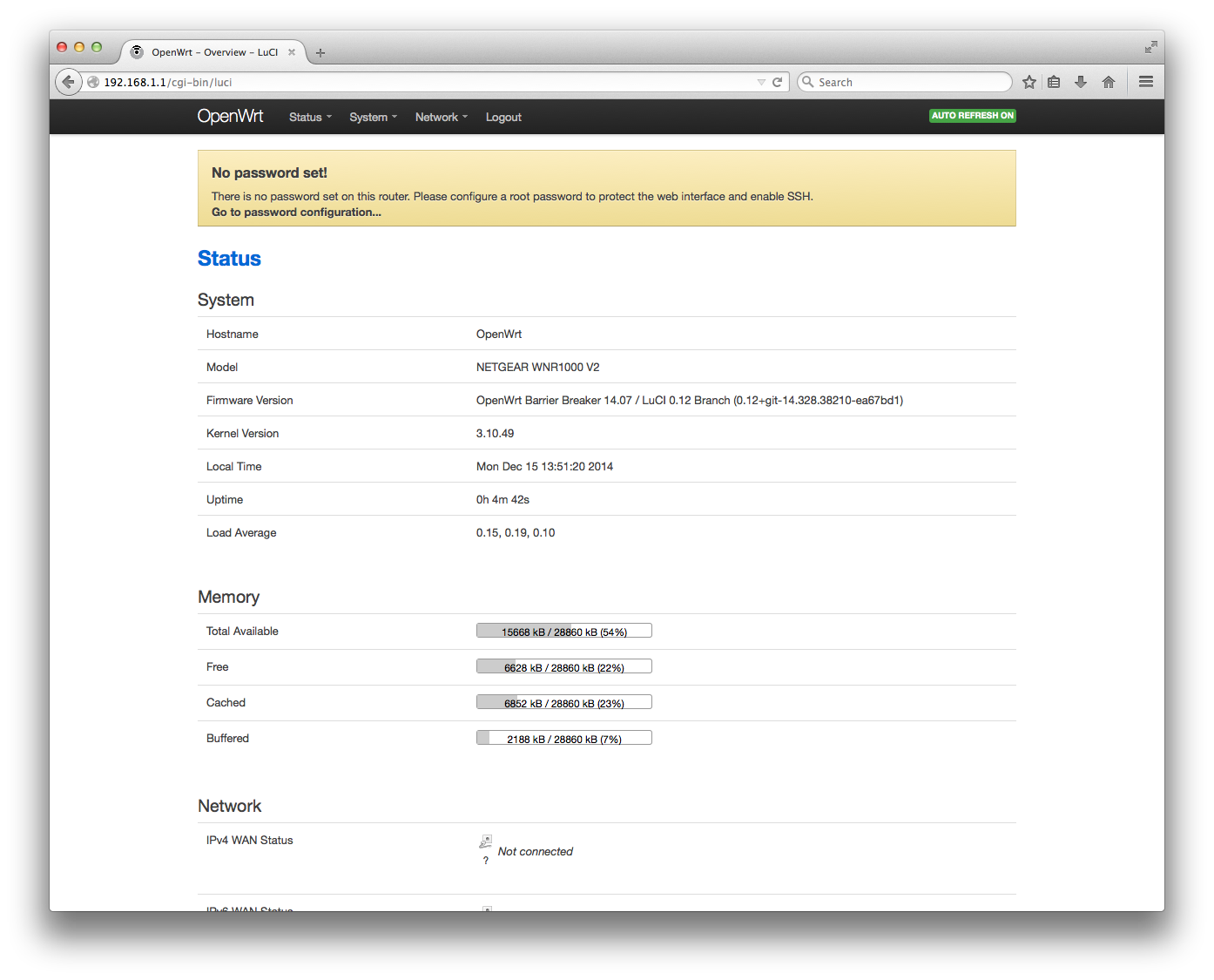
I’ve this router for the sole reason that it is a recommended piece of equipment for doing WiFu, but as as I previously mentioned, it fails to do its job.
In the mean time, I discovered that Netgear released some GPL firmwares which sit at the base of their firmwares. Basically you get a heavily modified OpenWrt Kamikaze (7.09) without a web interface and you need an ancient buildroot. You do have a command line utility for configuring it, but it is painful to do it so. I was unable to configure the WEP support in 1.0.0.5 GPL by using the same config as the 1.0.1.1 is using. Also, moving around the GPL firmware is difficult since there’s no vi support in busybox, but there’s a tftp client and cat.
The device itself is EOL, therefore the idea of using OpenWrt came up. I tried the generic AP81 build, as described here, but it corrupts the rootfs. The device boots in failsafe mode where you may flash a good firmware by using a TFTP client, therefore on the recovery side is good.
On the WikiDevi page for WNR1000v2 it is stated that it is using the same hardware as WNR612v2, but the WNR612v2 router has only two LAN ports, while WNR1000v2 has four. WNR612v2 itself uses hardware close to WNR2000v3 and both of these are supported by OpenWrt.
Flashing a WNR612v2 firmware, both factory and OpenWrt is impossible with the default images. The Netgear flashing support checks for the presence of a “magic number” in the firmware file. The procedure for finding that “magic number” is totally undocumented, therefore I’ve made a lot of wrong turns. I used the WNR612v2 “magic number” which is declared in OpenWrt, 0x32303631, and started to examine the firmware file. A quick grep confirmed that the byte sequence is present. Dumping the header of the file also confirmed it.
I repeated the procedure with the GPL firmware which I built for WNR1000v2 and with a factory firmware. It turns out that the magic number is: 0x31303031.
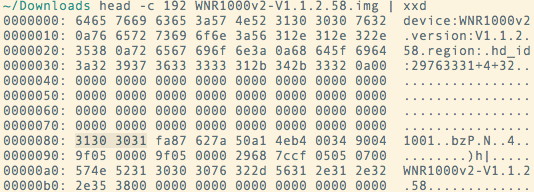
The rest of the work for adding WNR1000v2 support to OpenWrt was fairly straightforward after that as I used WNR2000v3 and WNR612v2 as template.
The rfkill and the WPS buttons don’t work at all. I don’t use WPS anyway, therefore for me is a non-issue. The lack of rfkill support may be a mild annoyance, but since this is my first router that actually has a button for toggling the wireless, doing it the usual way isn’t a big deal for me. I think the buttons may be controlled by GPIO, but I’m not sure and probably I’ll check this when my schedule allows it.
The patch and images are available into this Gist. The patch was made against the Barrier Breaker branch, r43617. The procedure for building your image if you don’t want to use my own image is described into the README.
I guess the next step is to add this support into the OpenWrt trunk, but I need to see if somebody is willing to merge the changes for supporting this device. I’ll need to test the patch and build more since the first merge with quilt wasn’t without issues. The purpose is to obtain a clean build in a single run.