Marius once told me about portspoof. A service to troll those who use various scanners by feeding the scanners with false results. Well, while the idea is good, I’m wary about a service like this as this is the kind of service where you wouldn’t want a buffer overflow.
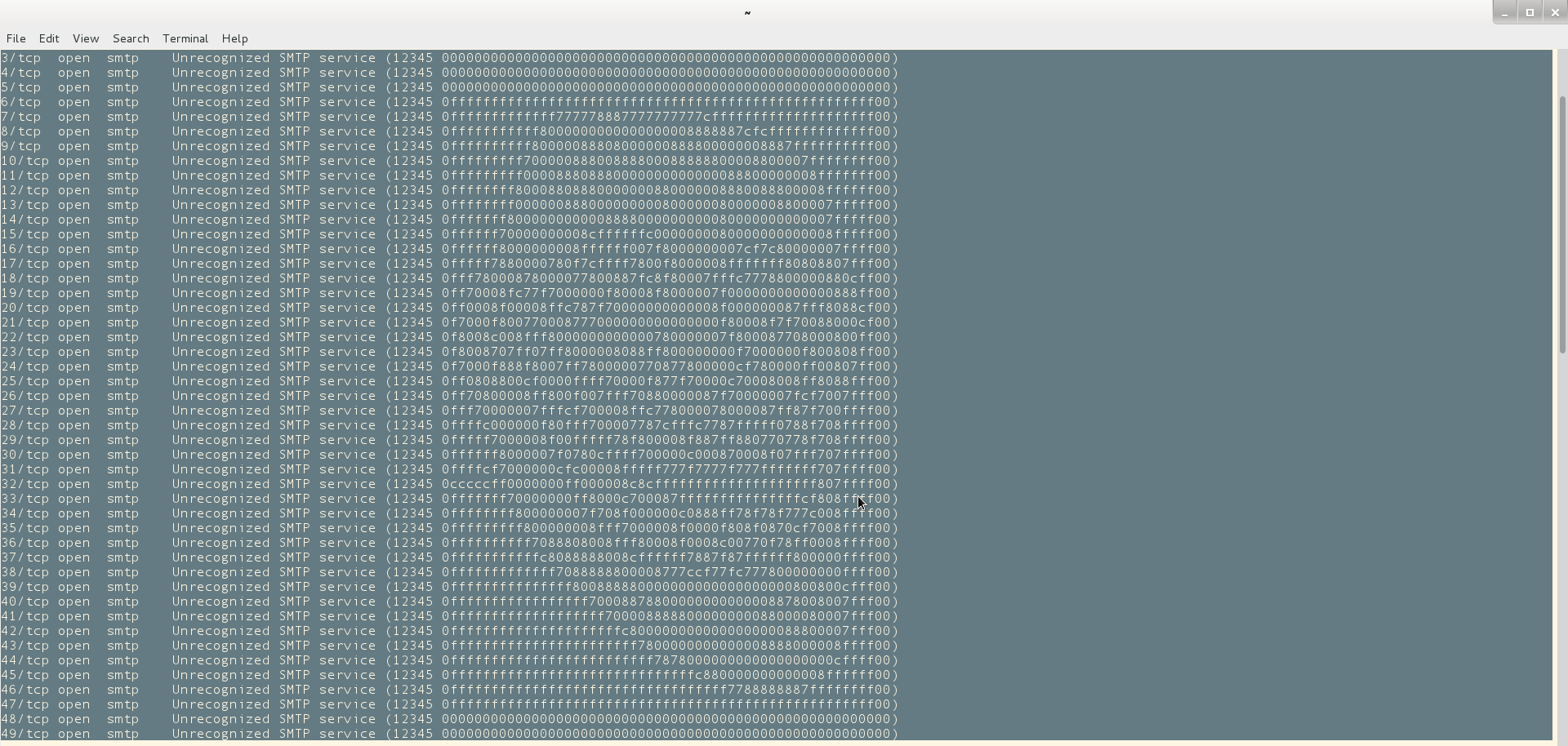
Giving it a run inside a VM, I noticed something odd when using nmap’s service and version detection probes. This happened on the lower ports (1-50). Then I started to look at something that started to look like a pattern, therefore I increased the port range to include 1-50. portspoof is indeed a tool that trolls baddies and pen testers.
Ran it with:
nmap -sV --version-all -p 1-50
1/tcp open smtp Unrecognized SMTP service (12345 0000000000000000000000000000000000000000000000000000000) 2/tcp open smtp Unrecognized SMTP service (12345 0000000000000000000000000000000000000000000000000000000) 3/tcp open smtp Unrecognized SMTP service (12345 0000000000000000000000000000000000000000000000000000000) 4/tcp open smtp Unrecognized SMTP service (12345 0000000000000000000000000000000000000000000000000000000) 5/tcp open smtp Unrecognized SMTP service (12345 0000000000000000000000000000000000000000000000000000000) 6/tcp open smtp Unrecognized SMTP service (12345 0ffffffffffffffffffffffffffffffffffffffffffffffffffff00) 7/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffff777778887777777777cffffffffffffffffffff00) 8/tcp open smtp Unrecognized SMTP service (12345 0fffffffffff8000000000000000008888887cfcfffffffffffff00) 9/tcp open smtp Unrecognized SMTP service (12345 0ffffffffff80000088808000000888800000008887ffffffffff00) 10/tcp open smtp Unrecognized SMTP service (12345 0fffffffff70000088800888800088888800008800007ffffffff00) 11/tcp open smtp Unrecognized SMTP service (12345 0fffffffff000088808880000000000000088800000008fffffff00) 12/tcp open smtp Unrecognized SMTP service (12345 0ffffffff80008808880000000880000008880088800008ffffff00) 13/tcp open smtp Unrecognized SMTP service (12345 0ffffffff000000888000000000800000080000008800007fffff00) 14/tcp open smtp Unrecognized SMTP service (12345 0fffffff8000000000008888000000000080000000000007fffff00) 15/tcp open smtp Unrecognized SMTP service (12345 0ffffff70000000008cffffffc0000000080000000000008fffff00) 16/tcp open smtp Unrecognized SMTP service (12345 0ffffff8000000008ffffff007f8000000007cf7c80000007ffff00) 17/tcp open smtp Unrecognized SMTP service (12345 0fffff7880000780f7cffff7800f8000008fffffff80808807fff00) 18/tcp open smtp Unrecognized SMTP service (12345 0fff78000878000077800887fc8f80007fffc7778800000880cff00) 19/tcp open smtp Unrecognized SMTP service (12345 0ff70008fc77f7000000f80008f8000007f0000000000000888ff00) 20/tcp open smtp Unrecognized SMTP service (12345 0ff0008f00008ffc787f70000000000008f000000087fff8088cf00) 21/tcp open smtp Unrecognized SMTP service (12345 0f7000f800770008777000000000000000f80008f7f70088000cf00) 22/tcp open smtp Unrecognized SMTP service (12345 0f8008c008fff8000000000000780000007f800087708000800ff00) 23/tcp open smtp Unrecognized SMTP service (12345 0f8008707ff07ff8000008088ff800000000f7000000f800808ff00) 24/tcp open smtp Unrecognized SMTP service (12345 0f7000f888f8007ff7800000770877800000cf780000ff00807ff00) 25/tcp open smtp Unrecognized SMTP service (12345 0ff0808800cf0000ffff70000f877f70000c70008008ff8088fff00) 26/tcp open smtp Unrecognized SMTP service (12345 0ff70800008ff800f007fff70880000087f70000007fcf7007fff00) 27/tcp open smtp Unrecognized SMTP service (12345 0fff70000007fffcf700008ffc778000078000087ff87f700ffff00) 28/tcp open smtp Unrecognized SMTP service (12345 0ffffc000000f80fff700007787cfffc7787fffff0788f708ffff00) 29/tcp open smtp Unrecognized SMTP service (12345 0fffff7000008f00fffff78f800008f887ff880770778f708ffff00) 30/tcp open smtp Unrecognized SMTP service (12345 0ffffff8000007f0780cffff700000c000870008f07fff707ffff00) 31/tcp open smtp Unrecognized SMTP service (12345 0ffffcf7000000cfc00008fffff777f7777f777fffffff707ffff00) 32/tcp open smtp Unrecognized SMTP service (12345 0cccccff0000000ff000008c8cffffffffffffffffffff807ffff00) 33/tcp open smtp Unrecognized SMTP service (12345 0fffffff70000000ff8000c700087fffffffffffffffcf808ffff00) 34/tcp open smtp Unrecognized SMTP service (12345 0ffffffff800000007f708f000000c0888ff78f78f777c008ffff00) 35/tcp open smtp Unrecognized SMTP service (12345 0fffffffff800000008fff7000008f0000f808f0870cf7008ffff00) 36/tcp open smtp Unrecognized SMTP service (12345 0ffffffffff7088808008fff80008f0008c00770f78ff0008ffff00) 37/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffc8088888008cffffff7887f87ffffff800000ffff00) 38/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffff7088888800008777ccf77fc777800000000ffff00) 39/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffffff800888880000000000000000000800800cfff00) 40/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffffffff70008878800000000000008878008007fff00) 41/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffffffffff700008888800000000088000080007fff00) 42/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffffffffffffc800000000000000000088800007fff00) 43/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffffffffffffff7800000000000008888000008ffff00) 44/tcp open smtp Unrecognized SMTP service (12345 0fffffffffffffffffffffffff7878000000000000000000cffff00) 45/tcp open smtp Unrecognized SMTP service (12345 0ffffffffffffffffffffffffffffffc880000000000008ffffff00) 46/tcp open smtp Unrecognized SMTP service (12345 0ffffffffffffffffffffffffffffffffff7788888887ffffffff00) 47/tcp open smtp Unrecognized SMTP service (12345 0ffffffffffffffffffffffffffffffffffffffffffffffffffff00) 48/tcp open smtp Unrecognized SMTP service (12345 0000000000000000000000000000000000000000000000000000000) 49/tcp open smtp Unrecognized SMTP service (12345 0000000000000000000000000000000000000000000000000000000) 50/tcp open smtp Unrecognized SMTP service (12345 0000000000000000000000000000000000000000000000000000000)
Really smooth guys, really smooth. Sometimes you have to see the big picture: